Text Classification
| Project Description | Engineering and supply chain processes are centralized around the use of the parts database to select, track, and warehouse parts. There are currently 28,000+ parts in the database, which is rapidly increasing as the company grows. Parts were not categorized in commodities. This project aimed to streamline engineering and supply chain processes by automatically categorizing all existing and future parts in the parts catalog. |
| Business Benefits | Ability to consolidate spent and direct it to one or two suppliers for that category of part, to benefit from mass order discounts
Ability to analyze spent based on commodity Giving more visibility on item categorization so that suppliers can be identified by commodity |
| Toolset | Python: Tensorflow, Sklearn, Pandas, Seaborn, Nltk |
| Methodology |
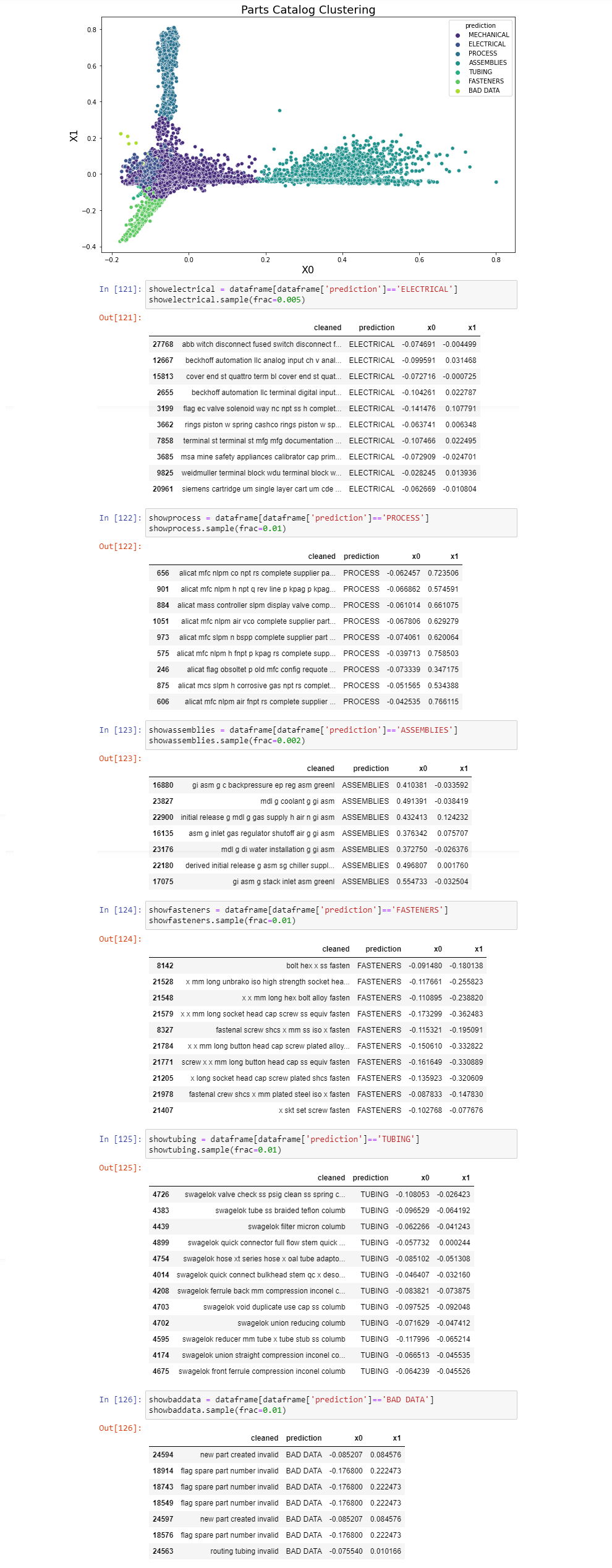
1) Run a K-Cluster analysis on the existing catalog to qualify data distinctness
2) Identify list of commodities 3) Manually create a training and testing set out of the 28,000 existing entries in the parts database 4) Create a supervised machine learning model using the Naive Bayes theorem, and train the model using the training set 5) Run model against the testing set for validation 6) Integrate the model into the parts catalog interface using REST.API |
| Achievements |
Allowed business to save over 300 hours of work versus the manual alternative, with a tight SAP migration deadline incoming
Future-proofed every future part database entry at a 95% accuracy, which is comparable to human error |